Apache provides an own memory and resource management known as pools. Pools are means to keep track of all resources ever used by Apache itself or any add-on module used with Apache. A pool can manage memory, sockets and processes, which are all valuable resources for a server system.
First of all pools are used to reduce the likelihood of programming errors. In C any program can allocate memory. If a program loses all references to that memory without marking the memory as free to use for any other program, it cannot be used by anyone until the program exits. This is called a memory leak. In programs mainly used in a desktop environment this does not do much harm since programs do not run very long and when exiting, the operating system frees all memory anyway. In a server environment the server software should potentially run for a very long time. Even small memory leaks in program parts that are repeatedly run can cause a server to crash.
Sockets are similarly sensitive. If a program registers for a socket and does not free that socket once it finished using it, no other program will be able to use it. Sockets also cause other resources like memory and CPU capacity to be occupied. If a part of a server program that is run repeatedly registers sockets and does not free them, the server will inevitably crash. Many servers work multithreaded which means more than one process or thread will run to do work for the server. Usually these processes will only be terminated by the administrator, if they do not exit by design. If a program starts never-ending processes repeatedly and forgets to ask them to terminate, the server's resources will be maxed out quickly and the server will crash.
With the pool concept, a developer registers any memory, socket or process with a pool that has a predetermined lifetime. Once the pool is destroyed, all resources managed by that pool are released automatically. Only a few routines that have been tested thoroughly will then take care of freeing all resources registered for this pool. That way only a few routines have to make sure that all resources are freed. Mistakes within those are a lot easier to find and this technology takes a burden of all other developers.
Additionally the pool technology improves performance. Usually a program uses memory once and deallocates it. That causes a lot of overhead, as the system has to allocate and deallocate and map to and from virtual memory. When using a lot of small bits of memory, that can reduce performance dramatically. Also, the system usually allocates a minimum number of bytes no matter how much memory was requested. That way small bits of memory are wasted. When done too often, that can add up to an amount worth taking care of.
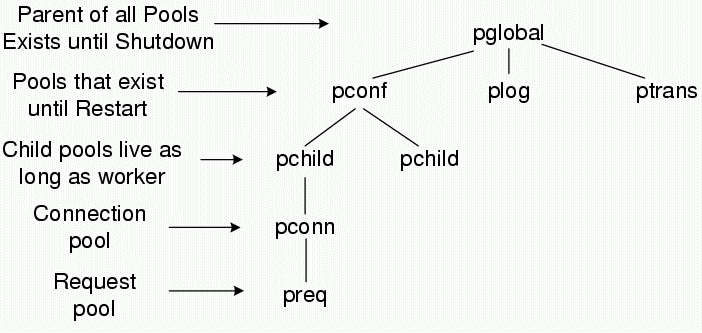
Apache has different built-in pools that each have a different lifetime. Figure 4.24 shows the hierarchy of the pools. The pool pglobal exists for the entire runtime of the server. The pchild pool has the lifetime of a child server. The pconn pool is associated with each connection and the preq pool for each request. Usually a developer should use the pool with the minimum acceptable lifetime for the data that is to be stored to minimize resource usage.
If a developer needs a rather large amount of memory or other resources and cannot find a pool with the acceptable lifetime, a sub pool to any of the other pools can be created. The program can then use that pool like any other and can additionally destroy that pool once it is not needed any longer. If the program forgets to destroy the pool, it will automatically be destroyed once the Apache core destroys the parent pool. All pools are sub pools of the main server pool pglobal. A connection pool is a sub pool of the child server pool handling the connection and all request pools are sub pools of the corresponding connection pools.
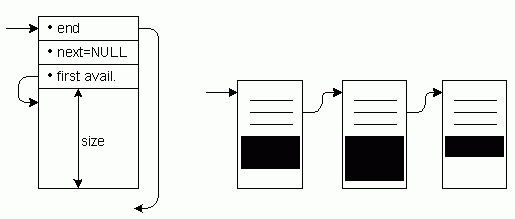
Internally, a pool is organized as a linked list of sub pools, blocks, processes and callback functions. Figure 4.25 gives a simple view of a block and an example of a linked list of blocks.
If memory is needed, it should be allocated using predefined functions. These functions do not just allocate the memory but also keep references to that memory to be able to deallocate it afterwards. Similarly processes can be registered with a pool to be destroyed upon death of the pool. Additionally each pool can hold information about functions to be called prior to destroying all memory. That way file handlers and as such sockets can be registered with a pool to be destroyed.
When a pool is destroyed, Apache first calls all registered cleanup functions. All registered file handlers and that way also sockets are closed. After that, a pool starts to terminate all registered and running processes. When finished with that, all blocks of memory are freed. Usually Apache does not really free the memory for use by any other program but deletes it from the pool and adds it to a list of free memory that is kept by the core internally. That way the costly procedure of allocating and deallocating memory can be cut down to a minimum. The core is now able to assign already allocated memory to the instance in need. It only needs to allocate new memory if it has used up all memory that was deallocated before.
Apache allocates memory one block at a time. A block is usually much bigger than the memory requested by modules. Since a block always belongs to one pool, it is associated with the pool once the first bit of memory of that block is used. Subsequent requests for memory are satisfied by memory left over in that pool. If more memory is requested than left over in the last block, a new block is added to the chain. The memory left over in the previous block is not touched until the pools is destroyed and the block is added to the list of free blocks.
Since blocks are not deallocated but added to a list of free blocks, Apache only needs to allocate new blocks once the free ones are used up. That way the performance overhead is heavily reduced, as the system seldom needs to be involved in memory allocation. Under most circumstances also the amount of memory used to store the same amount of information is smaller compared to conventional memory allocation, as Apache always assigns as much memory as needed without a lower limit. The size of a block can be configured using the Apache configuration.
Since each pool handles the cleanup of resources registered with it itself, the necessary API functions are mainly used to allocate resources or to register already created resources with a pool for cleanup. However, some resources can be cleaned up manually before the pool is destroyed.
When allocating memory, developers can use two different functions. ap_palloc and ap_pcalloc both take the pool and the size of the memory needed as arguments and return a pointer to the memory now registered and available to use. However ap_pcalloc clears out the memory before returning the pointer.
The function ap_strdup is used to allocate memory from a pool and place a copy of a string in it that is passed to the function as an argument. ap_strcat is used to initialize a new allocated string with the concatenation of all string supplied as arguments.
Basically any resource can be registered with a pool by supplying callback functions. Here the function which is to be called to free or terminate the resource and the parameters are registered. Upon the end of the lifetime of a pool these functions are called. That way any type of resource can make use of the pool technology.
For file descriptors and as such sockets, as these are file descriptors, the core offers equivalents to the fopen and fclose commands. These make use of the callback function registration. They register a function that can be called to close file descriptors when the pool is destroyed.
Additionally, a pool can manage processes. These are registered with the pool using the ap_note_subprocess function if the processes already exist. The better way is to use ap_spawn_child as that function also automatically registers all pipes and other resources needed for the process with the pool.
Sub pools are the solution if an existing pool is not suitable for a task that may need a large amount of memory for a short time. Sub pools are created using the ap_make_sub_pool function. It needs the parent pool handed over as argument and returns the new pool. Now this pool can be used to allocate resources relatively independent from the parent pool. The advantage is that the pool can be cleared (ap_clear_pool) or even destroyed (ap_destroy_pool) without affecting the parent pool. However when the parent pool the architecture shown in [fig: Internals: preforking BD]is destroyed, the sub pool is destroyed automatically.
| Apache Modeling Portal 2004-10-29 |