RFCs (Request For Comments) are a collection of notes about the Internet which started in 1969. These notes describe many standards concerning computer communication, networking protocols, procedures, programs and concepts. All Internet standards are defined in the RFCs.
To become a standard, an RFC has to traverse three steps called Internet Standards Track:
For further information on RFCs look at http://www.faqs.org/rfcs. This site also contains links to all involved Internet Related Standard Organizations, like the W3C (http://www.w3c.org).
TCP/IP is the most commonly used network protocol worldwide and all nodes connected to the Internet use it. TCP/IP consists of the 3 main protocols TCP (Transmission Control Protocol), UDP (User Data Protocol) and IP (Internet Protocol). UDP is a less important protocol using the lower-level Protocol IP as well. For more details, have a look at ``Computer Networks'' by Andrew Tanenbaum [6].
TCP and UDP are transmission protocols that use IP to transmit their data. While IP is responsible for transmitting packets to the destination at best effort, TCP and UDP are used to prepare data for sending by splitting them in packets.
TCP (Transmission Control Protocol) provides a connection for bi-directional communication between two partners using two data streams. It is therefore called a connection-oriented protocol. Before sending or receiving any data, TCP has to establish a connection channel with the target node. To provide the channel for the two data streams it has to split the data into packets and ensure that packets arrive without error and are unpacked in the proper order. That way an application using TCP does not have to take precautions for corrupted data transfer. TCP will make sure data transfer is completed successfully or report an error otherwise.
UDP (User Data Protocol) on the other hand is a much simpler technique for delivering data packets. It just adds a header to the data and sends them to its destination, regardless whether that node exists or expects data. UDP does not guarantee that packets arrive, nor does it ensure they arrive in the order they were sent. If packets are transmitted between two networks using different paths they can arrive in a wrong order. It's the application that has to take care of that. However, for applications needing fast transfer without overhead for data that is still usable even if single packets are missing or not in order, UDP is the protocol in choice. Most voice and video streaming applications therefore use UDP.
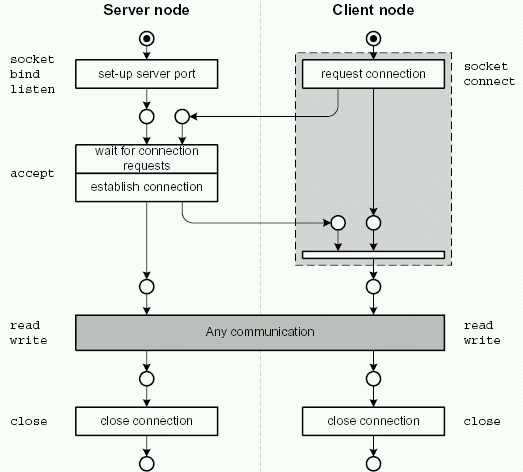
A TCP connection can only be established between two nodes: A client node sending a connection request and a server node waiting for such connection requests. After receiving a connection request, the server will respond and establish the connection. Then both nodes can send and receive data through the connection, depending on the application protocol. When finished, any node (but usually the client) can close the connection. This behavior is shown in figure 2.3. Here you also see the operating system calls used to control the sockets -- see appendix A.3 for details.
An address of a TCP or UDP service consists of the IP address of the machine and a port number. These ports enable hosts using TCP/IP to offer different services at one time and to enable clients to maintain more than one connection to one single server. On a server, ports are used to distinguish services. HTTP servers usually use the well-known port 80 to offer their services. Other standard ports are 53 for DNS and 21 for FTP for example. In any situation, every connection on a network has different pairs of target and source addresses (IP address + port number).
IP, the Internet Protocol, is responsible for sending single packets to their destination nodes. This is accomplished by assigning each computer a different IP address. Each IP address consists of 32 bits usually represented in 4 dotted decimals each ranging from 0 through 255. An example for a valid IP address is 123.123.123.123. IP addresses can be distinguished by the networks they belong to. The IP name-space is separated into networks by dividing the 32 Bits of the address into network and host address bits. This information is used for routing the packets to its destination.
As covered by the previous chapter, each node on the Internet can be identified by a unique IP address. Unfortunately IP addresses are numbers which are neither user friendly nor intuitive.
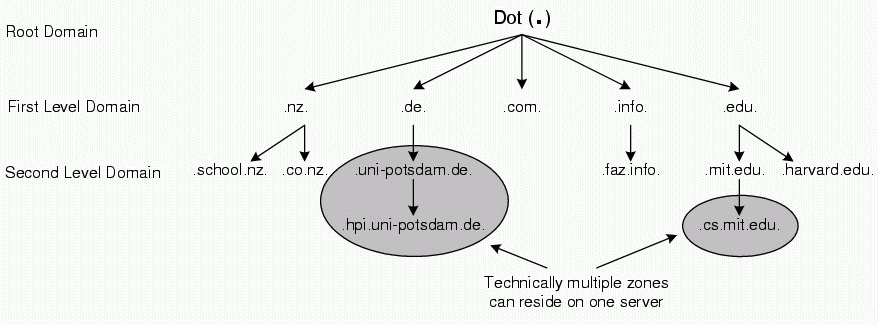
As a solution to that problem, DNS maps user-friendly names to IP addresses. Names used in the DNS are organized in a hierarchical name-space. The name space is split up into domains. The topmost domain is the . (Dot) domain. Domains below that, referred to as first-level domains, split up the name-space by country. The first-level domains com, net, org and edu are an exception to that rule. Originally they were intended to be used in the United States only, but now are used all over the world. More first level domains will be available. Individuals can register second-level domains within almost any of these domains.
DNS Servers are organized hierarchically according to their responsibilities, forming a globally distributed database. Each DNS Server is an authority for one or multiple zones. Each zone can contain one branch of the name-space tree. A zone itself can delegate sub-zones to different name servers. The root name servers are responsible for the 'Dot' domain and delegate a zone for each first-level domain to the name servers of the corresponding country domains. These on the other hand delegate zones for each name registered to name servers supplied by or for the parties that own the second level domains. These name servers contain entries for sub-zones and/or host-names for that zone. Figure 2.4 shows zones and their dependencies.
DNS can be queried using either recursive or iterative lookup requests. When using an iterative request, a DNS server will return either
HTTP is the primary transfer protocol used in the World Wide Web. The first version of HTTP that was widely used was version 1.0. After the Internet began to expand rapidly, deficiencies of the first version became apparent. HTTP 1.1, the version used today, addressed these issues and extended the first version. Although HTTP doesn't set up a session (stateless protocol) and forms a simple request-response message protocol, it uses connections provided by TCP/IP as transport protocol for its reliability. HTTP is designed for and typically used in a client-server environment.
With HTTP, each information item available is addressed by a URI (Uniform Resource Identifier), which is an address used to retrieve the information. Even though URIs and URLs historically were different concepts, they are now synonymously used to identify information resources. URL(G) is the more widely used term. An example for a URL is: http://apache.hpi.uni-potsdam.de/index.php. It would result in the following request
HOST: apache.hpi.uni-potsdam.de
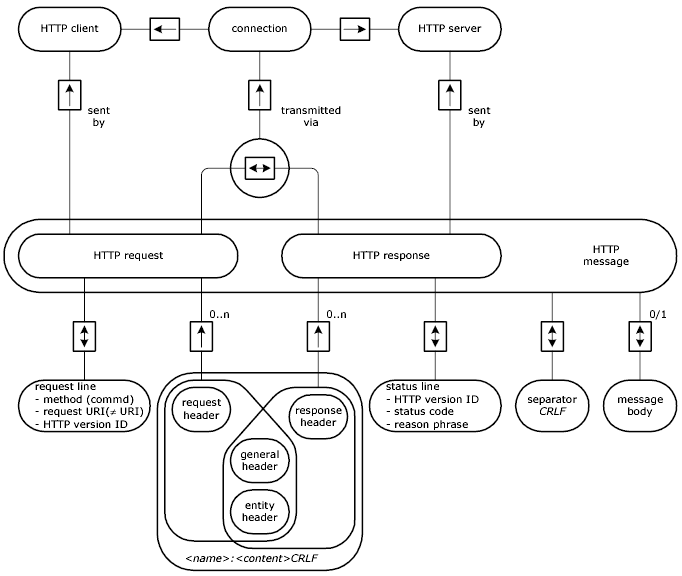
HTTP data transfer is based on messages. A request from a client as well as a response from a server is encoded in a message. Each HTTP message consists of a message header (G) and can contain a message body.
An HTTP header can be split up into 4 parts.
Header and body of an HTTP message are always separated by a blank line. Most header fields are not mandatory. The simplest request will only require the request line and, since HTTP 1.1, the general header field "HOST" (see section 2.3.4). The simplest response only contains the status line.
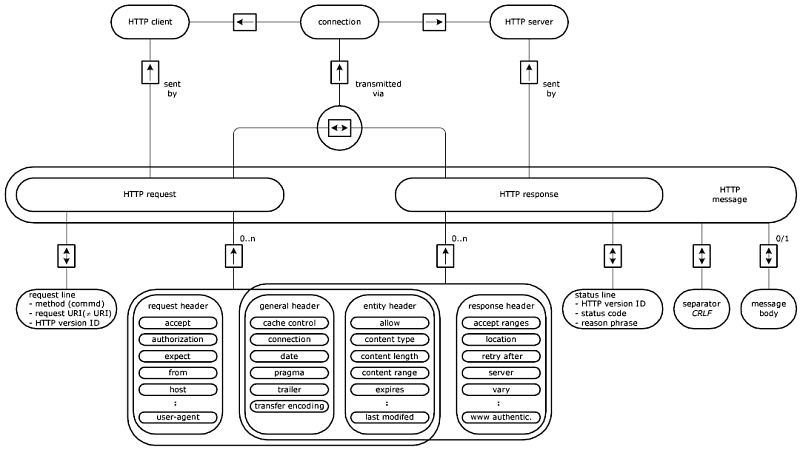
An example request/response message pair is shown in figure 2.5. The E/R diagrams in figures 2.6 and 2.7 show more details of the structure of the HTTP messages..
The next sections cover aspects of HTTP including their header fields. Important header fields not covered later are:
HTTP methods are similar to commands given to an application. Depending on the method used in the request, the server's response will vary. Successful responses to some request methods do not even contain body data.
The HTTP/1.1 standard defines the methods GET, POST, OPTIONS, HEAD, TRACE, PUT, DELETE, CONNECT. The most often used methods are GET and POST.
All other methods are rarely used and will only be covered briefly:
As stated above, each server reply always contains a status code. Generally server replies are structured in 5 different categories. Status Codes are three digit numbers. Each category can be identified by the first digit. These Categories split up the total set of status codes by their meaning:
Virtual Hosts is a concept which allows multiple logical web servers to reside on one physical server, preferably with one IP Address. The different concepts are:
HTTP/1.1 introduced the Host header field, which is mandatory in any HTTP/1.1 request. Therefore a server can now host multiple domains on the same IP address and port, by distinguishing the target of the request using the information supplied in the HOST header field.
Usually the body of an HTTP response includes data for user interpretation. Different users might be better served with different versions of the same document. Apache can keep multiple versions of the same document, in either a different language or a different format. The included standard page displayed right after Apache is installed is an example as there are multiple versions each in a different language. Two ways can be distinguished for determining the best version for a user: server driven and client driven content negotiation.
With server driven content negotiation, the server decides which version of the requested content is sent to the client. Using the Accept header field, the client can supply a list of formats that would be acceptable to the user, regarding format as well as language. The server will then try to select the best suitable content.
Using server driven content negotiation, the client has no influence on the choice made by the server if none of the accepted formats of the source are available. Since it is not practicable to list all possible formats in the desired order, the client can use the Accept Header with the value Negotiate. The server will then reply with a list of available formats instead of the document. In a subsequent request the client can then directly request the chosen version.
HTTP/1.0 limited one TCP connection to last for one single request. When HTTP was developed, HTML documents usually consisted of the HTML file only, so the protocol was appropriate. As web pages grew to multimedia sites, one single page consisted of more than one document due to images, sounds, animations and so forth. A popular news web-site's index page today needs 150 different file requests to be displayed completely. Opening and closing a TCP connection for every file imposed a delay for users and a performance overhead for servers. Client and server architects soon added the header field "Connection: keep-alive" to reuse TCP connections, despite the fact that it was not part of the HTTP standard.
HTTP/1.1 therefore officially introduced persistent connections and the Connection header field. By default a connection is now persistent unless specified otherwise. Once either partner does not wish to use the connection any longer, it will set the header field "Connection: close" to indicate the connection will be closed once the current request has been finished. Apache offers configuration directives to limit the amount of requests for one connection and a time-out value, after which any connection has to be closed when no further request is received.
Statistically, it is a well-known fact that a very high percentage of the HTTP traffic is accumulated by a very low percentage of the available documents on the Internet. Also a lot of these documents do not change over a period of time. Caching is technique used to temporarily save copies of the requested documents either by the client applications and/or by proxy servers in between the client application and the web server.
A proxy server is a host acting as a relay agent for an HTTP request. A client configured to use a proxy server will never request documents from a web server directly. Upon each request, it will open a connection to the configured proxy server and ask the proxy server to retrieve the document on its behalf and to forward it afterwards. Proxy Servers are not limited to one instance per request. Therefore a proxy server can be configured to use another proxy server. The technique of using multiple proxy servers in combination is called cascading. Proxy Servers are used for two reasons:
Even though caching is a favorable technique, it has its problems. When caching a document, a cache needs to determine how long that document will be valid for subsequent requests. Some information accessible to a cache is also of private or high security nature and should in no case be cached at all. Therefore cache control is a complex function that is supported by HTTP with a variety of header fields. The most important are:
| Apache Modeling Portal 2004-10-29 |