Modules are pieces of code which can be used to provide or extend functionality of the Apache HTTP Server. Modules can either be statically or dynamically included with the core. For static inclusion, the module's source code has to be added to the server's source distribution and to compile the whole server. Dynamically included modules add functionality to the server by being loading as shared libraries during start-up or restart of the server. In this case the module mod_so provides the functionality to add modules dynamically. In a current distribution of either Apache 2.0 or Apache 1.3, all but very basic server functionality has been moved to modules.
Modules interact with the Apache server via a common interface. They register handlers for hooks in the Apache core or other modules. The Apache core calls all registered hooks when applicable, that means when triggering a hook. Modules on the other hand can interact with the server core via the Apache API. Using that API each module can access the server's data structures, for example for sending data or allocating memory.
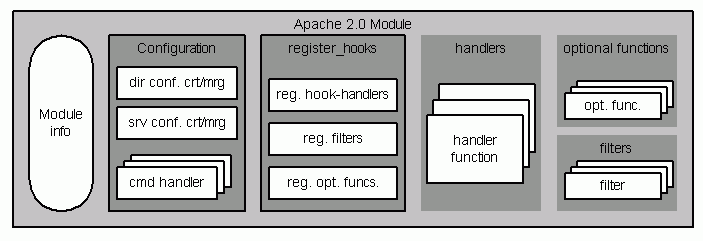
Each module contains a module-info, which contains information about the handlers(G) provided by the module and which configuration directives the module can process. The module info is essential for module registration by the core.
All Apache server tasks, be it master server or child server, contain the same executable code. As the executable code of an Apache task consists of the core, the static modules and the dynamically loaded ones, all tasks contain all modules.
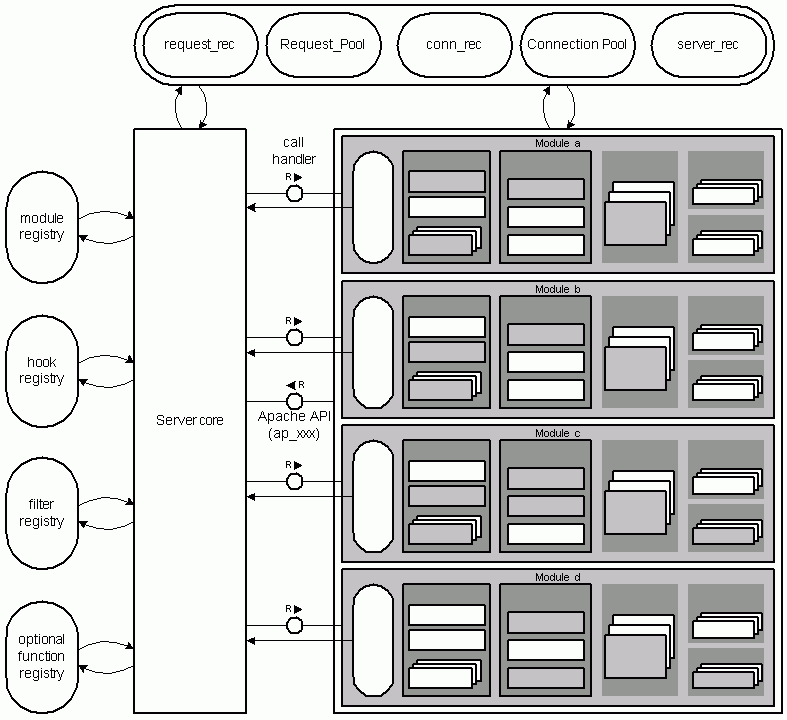
As you can see in figure 3.4, Modules and the Core can interact in two different ways. The server core calls module handlers registered in its registry. The modules on the other hand can use the Apache API for various purposes and can read and modify important data structures like the request/response record request_rec and allocate memory in the corresponding pools.
A module can provide different kinds of handlers:
A hook is a transition in the execution sequence where all registered handlers will be called. It's like triggering an event which results in the execution of the event handlers. The implementation of a hook is a hook function named ap_run_HOOKNAME which has to be called to trigger the hook.
Two types of calling handlers for a hook can be distinguished:
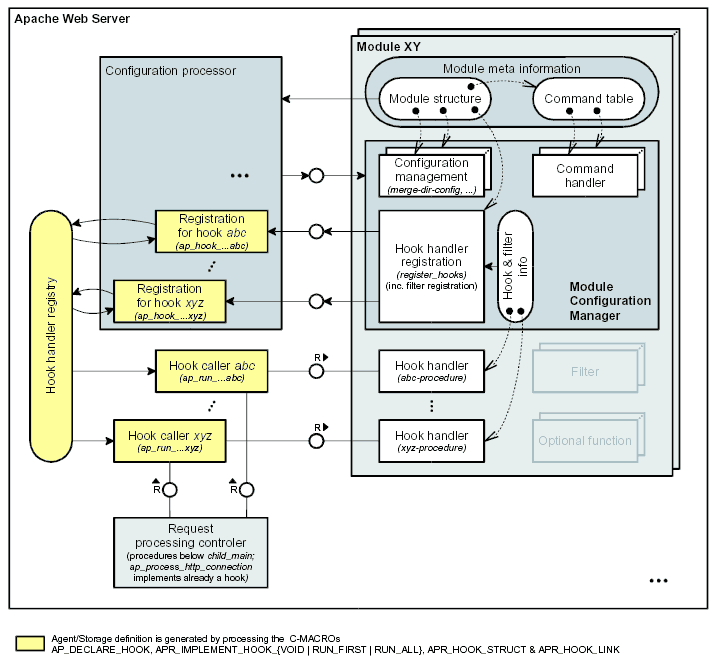
Figure 3.5 shows how hooks and handlers interact in Apache: A hook ABC has to be defined by some C macros (AP_DECLARE_HOOK, etc, see bottom line}. This results in the creation of a registration procedure ap_hook_ABC, a hook caller procedure ap_run_ABC and an entry in the hook handler registry which keeps information about all registered handlers for the hook with their modules and their order. The module (meta) info at the top points to the hook handler registration procedure (register_hooks) which registers the handlers for the hooks calling the ap_hook_xxx procedures. At the bottom, an agent called ``request processing controler'' is a representative of all agents triggering hooks by calling the ap_run_xxx procedures which read the hook handler registry and call all or one registered handler.
The order of calling handlers for a hook can be important. In Apache 1.3, the order of the module registration determined the order in which their handlers would be called. The order could be altered in the configuration file but was the same for all 13 hooks. In Apache 2, this has changed. The hook registry can store an individual order of handlers for each hook. By registering a handler for a hook using the ap_hook_xxx procedure, a module can supply demands for its position in the calling sequence. It can name modules that's handlers have to be called first or afterwards, or it can try to get the first or the last position.
A module can provide an own set of directives which can be used in the configuration files. The configuration processor of the core therefore delegates the interpretation of a directive to the corresponding command handler which has been registered for the directive. In figure 3.5 the module (meta) info at the top points to the configuration management handlers of the module (create-dir-config, merge-dir-config, etc.) and to the command table which contains configuration directives and the pointers to the corresponding command handlers.
The configuration management handlers have the purpose to allocate memory for configuration data read by the command handlers and to decide what to do if configuration parameters differ when hierarchically merging configuration data during request processing.
An Apache 2.0 module can also register optional functions and filters. Optional Functions are similar to hooks. The difference is that the core ignores any return value from an optional function. It calls all optional functions regardless of errors. So optional functions should be used for tasks that are not crucial to the request-response process at all.
The most important step in the request-response loop is calling the content handler which is responsible for sending data to the client.
In Apache 1.3, the content handler is a handler very much like any other. To determine which handler to call Apache 1.3 uses the type_checker handler which maps the requested resource to a mime-type or a handler. Depending on the result, the Apache Core calls the corresponding content handler which is responsible for successfully completing the response. It can write directly to the network interface and send data to the client. That makes request handling a non-complex task but has the disadvantage that usually only one module can take part in handling the request. If more than one content handler have been determined for the resource, the handler that was registered first is called. It is not possible that one handler can modify the output of another without additional changes in the source code.
Apache 2.0 extends the content handler mechanism by output filters . Altough still only one content handler can be called to send the requested resource, filters can be used to manipulate data sent by the content handler. Therefore multiple modules can work cooperatively to handle one request. During the mime-type definition phase in Apache 2.0 multiple filters can be registered for one mime-type together with an order in which they are supposed to handle the data. Each mime-type can be associated with a different set of modules and a differing filter order. Since a sequenced order is defined, these filters form a chain called the output filter chain.
When the Content handler is called, Apache 2.0 initiates the output filter chain. Within that chain a filter performs actions on the data and when finished passes that data to the next filter. That way a number of modules can work together in forming the response. One example is a CGI content handler handing server side include tags down the module chain so that the include module can handle them.
Apache 2 Filters(G) are handlers for processing data of the request and the response. They have a common interface and are interchangeable.
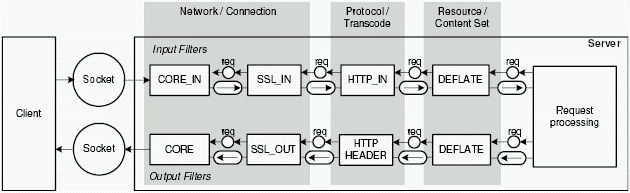
In figure 3.6 you see two example filter chains: The input filter chain to process the data of the request and the output filter chain to process the data of the response (provided by the content handler). The agent ``Request processing'' triggers the input filter chain while reading the request. An important use of the input filter chain is the SSL module providing secure HTTP (HTTPS) communication.
The output filter chain is triggered by the content handler. In our example, the Deflate output filter compresses the resource depending on its type.
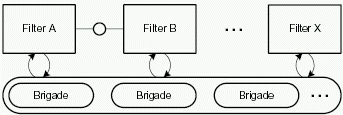
To improve performance, filters work independently by splitting the data into buckets and brigades (see figure 3.7) and just handing over references to the buckets instead of writing all data to the next filter's input (see figure 3.8). Each request or response is split up into several brigades. Each brigade consists of a number of buckets.One filter handles one bucket at a time and when finished hands the bucket on to the next filter. Still the order in which the filters hand on the data is kept intact.
Besides separating filters into input and output filters, 3 different categories can be distinguished:
Even though in Apache 2.0 handlers for hooks are registered differently from Apache 1.3, the predefined hooks are very alike in both versions and can be distinguished into 3 different categories by their purpose and their place in the runtime sequence:
During start-up or restart, the Apache master server reads and processes the configuration files. Each modules can provide a set of configuration directives. The configuration processor of the core will call the associated command handler every time it encounters a directive belonging to a module.To prepare resources for storing configuration data, a module can register handlers for the following hooks:
Apache is a multitasking server. During start-up and restart, there is only one task performing initialization and reading configuration. Then it starts spawning child server tasks which will do the actual HTTP request processing. Depending on the multiprocessing strategy chosen, there may be a need for another initialization phase for each child server to access resources needed for proper operation, for example connect to a database. If a child server terminates during restart or shutdown, it must be given the opportunity to release its resources.
![[*]](crossref.png) ).
The pre_config handler is executed by the master server task and
can take advantage of the privileges (if executed by root/administrator).
).
).
The pre_config handler is executed by the master server task and
can take advantage of the privileges (if executed by root/administrator).
).
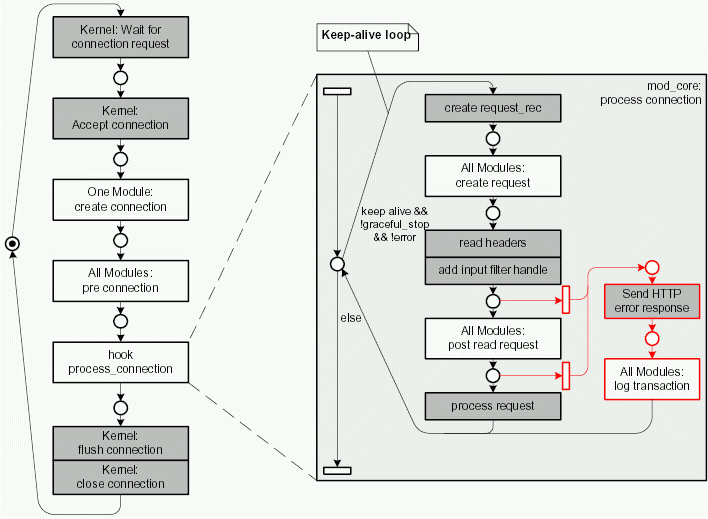
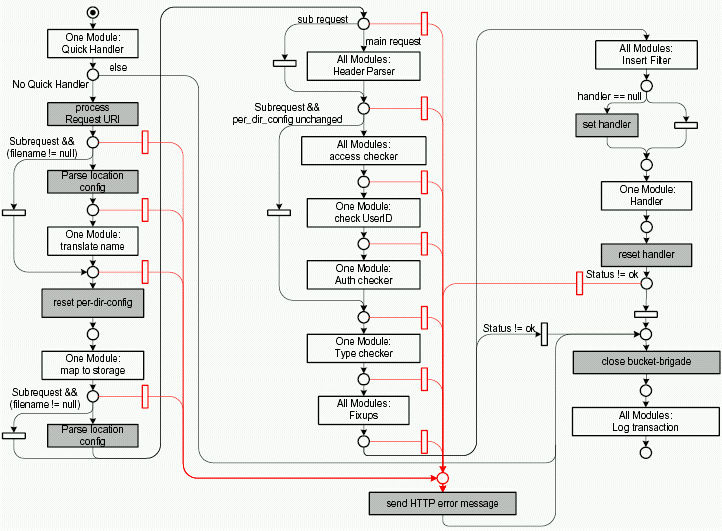
All following handlers actually deal with request handling and are part of the request-response loop. Figures 3.9 and 3.10 illustrate the sequential structure of that process.
Figure 3.9 shows the behavior of Apache during the request-response loop. Most of the hooks shown here didn't exist in Apache 1.3.
Figure 3.10 shows how Apache processes an HTTP request. The special case of internal requests will not be explained further.
This module is discussed in detail to illustrate the structure of Apache Modules by a practical example.
Both distributions of Apache 1.3 and 2.0 include mod_cgi. This module is used to process CGI programs that can create dynamic web content. Due to the architectural differences between versions 1.3 and 2.0 discussed in the previous chapter the two versions of the module are different.
Usually the module info can be found at the end of the main source file for the specific module. In mod_cgi for Apache 1.3 the module info contains references to 2 handlers:
{
STANDARD_MODULE_STUFF,
NULL, /* initializer */
NULL, /* dir config creater */
NULL, /* dir merger - default is to override */
create_cgi_config, /* server config */
merge_cgi_config, /* merge server config */
cgi_cmds, /* command table */
cgi_handlers, /* handlers */
NULL, /* filename translation */
NULL, /* check_user_id */
NULL, /* check auth */
NULL, /* check access */
NULL, /* type_checker */
NULL, /* fixups */
NULL, /* logger */
NULL, /* header parser */
NULL, /* child_init */
NULL, /* child_exit */
NULL /* post read-request */
};
{
{"ScriptLog", set_scriptlog, NULL, RSRC_CONF, TAKE1,
"the name of a log for script debugging info"},
{"ScriptLogLength", set_scriptlog_length, NULL, RSRC_CONF, TAKE1,
"the maximum length (in bytes) of the script debug log"},
{"ScriptLogBuffer", set_scriptlog_buffer, NULL, RSRC_CONF, TAKE1,
"the maximum size (in bytes) to record of a POST request"},
{NULL}
};
{
{CGI_MAGIC_TYPE, cgi_handler},
{"cgi-script", cgi_handler},
{NULL}
};
When the type_checker decided that the mod_cgi module should handle a request and then the core calls the content handler, it actually calls the function cgi_handler.
Cgi_handler first prepares for executing a CGI by checking some pre conditions, like "Is a valid resource requested? ". Then it creates a child process by calling ap_bspawn_child that will execute the CGI program. Parameters for that function are among others the name of the function to be called within the process, here cgi_child, and a child_stuff struct that contains the whole request record. Child_cgi itself then prepares to execute the interpreter for the script and calls ap_call_exec, which is a routine that takes the different operating systems into account and uses the exec routines working for the currently used operating system. After that all output by the script is passed back to the calling functions until it reaches the cgi_handler handler function that then sends the data to the client including the necessary HTTP header.
In the version for Apache 2.0 the module info is much smaller. Most references to handlers for hooks are now replaced by the reference to the function register_hooks. All handlers except the handlers for the configuration management hooks are now dynamically registered using that function.
{
STANDARD20_MODULE_STUFF,
NULL, /* dir config creater */
NULL, /* dir merger -- default is to override */
create_cgi_config, /* server config */
merge_cgi_config, /* merge server config */
cgi_cmds, /* command apr_table_t */
register_hooks /* register hooks */
};
{
static const char * const aszPre[] = { "mod_include.c", NULL };
ap_hook_handler(cgi_handler, NULL, NULL, APR_HOOK_MIDDLE);
ap_hook_post_config(cgi_post_config, aszPre, NULL, APR_HOOK_REALLY_FIRST);
}
In mod_cgi for Apache 2.0, the function cgi_handler is the start of the output filter chain. At first it behaves very much like its Apache 1.3 pendant. It prepares to start a process to execute the CGI program. It then retrieves the response data from that process. Most of the execution is done in the cgi_child function.
After it has got the response from the program, its task is to hand the just created brigade down the filter chain. That is done at the end of the function with a call to ap_pass_brigade. For example, it is now possible for a cgi program to output SSI (server-side includes) commands which are then processed by the include module. In that context the include module must have registered a filter that now gets the data from mod_cgi. Of course that depends on the configuration for the corresponding MIME type.
The Apache API summarizes all possibilities to change and enhance the functionality of the Apache web server. The whole server has been designed in a modular way so that extending functionality means creating a new module to plug into the server. The previous chapter covered the way in which modules should work when the server calls them. This chapter explains how modules can successfully complete their tasks.
Basically, all the server provides is a big set of functions that a module can call. These functions expect complex data structures as attributes and return complex data structures. These structures are defined in the Apache sources.
Again the available features differ between the two major Versions of Apache 1.3 and 2.0. Version 2.0 basically contains all features of 1.3 and additionally includes the Apache Portable Runtime (APR) which enhances and adds new functionality.
Apache offers functions for a variety of tasks. One major service apache offers to its modules is memory management. Since memory management is a complex task in C and memory holes are the hardest to find bugs in a server, Apache takes care of freeing all used memory after a module has finished its tasks. To accomplish that, all memory has to be allocated by the apache core. Therefore memory is organized in pools. Each pool is associated with a task and has a corresponding lifetime. The main pools are the server, connection and request pool. The server pool lives until the server is shut down or restarted, the connection pool lives until the corresponding connection is closed and the request pool is created upon arrival and destroyed after finishing a request. Any module can request any type of memory from a pool. That way the core knows about all used memory. Once the pool has reached the end of its lifetime, the core deallocates all memory managed by the pool. If a module needs memory that should even have a shorter lifetime than any of the available pools a module can ask Apache to create a sub pool. The module can then use that pool like any other. After the pool has served its purpose, the module can ask Apache to destroy the pool. The advantage is that if a module forgets to destroy the sub pool, the core only has to destroy the parent pool to destroy all sub pools.
Additionally Apache offers to take care of Array and Table management, which again makes memory management easier. Arrays in Apache can grow in size over time and thus correspond to Vectors in Java and Tables contain key/value pairs and thus are similar to hash tables. Section 4.6 provides further informations about the pool technology.
Apache offers a variety of functions that require special parameters and return values of special structure. Therefore it is essential to know about the Data types used by the Apache API. Most fields contained in any of these records should not be changed directly by a module. Apache offers API functions to manipulate those values. These functions take necessary precautions to prevent errors and ensure compatibility in later versions.
Besides memory management Apache assists the modules in various ways. The main target of the API is full abstraction from the operating system and server configuration. Apache offers functions for manipulating Apache data structures and can take precautions the module does not need to know about. The core can also perform system calls on behalf of the module and will use the routines corresponding to the operating system currently in use. That way each module can be used in any operating systems environment. For example the Apache API includes functions for creating processes, opening communication channels to external processes and sending data to the client. Additionally Apache offers functions for common tasks like string parsing.
Within the Apache API, functions can be classified into the following groups:
Version 2.0 of Apache introduces the Apache Portable Runtime, which adds and enhances functionality to the Apache API. Due to the APR Apache can be considered a universal network server that could be enhanced to almost any imaginable functionality. That includes the following platform independent features:
| Apache Modeling Portal 2004-10-29 |