The most influencing factor when creating multitasking architectures is the operating system in use. With every operating system the environment and their performance attributes change. Therefore certain multitasking architectures are incompatible or not performant enough on certain operating systems. The second major influencing factor are the use-scenarios. Depending on how much processing is involved with a single request, how many requests a server will have to handle and/or whether requests logically depend on each other, certain architectures might be more advantageous than others.
Section 4.3.1 explains how a common multitasking network server architecture works and discusses its shortcomings if used as an HTTP server. The Apache server architecture will be shown in section 4.3.2.
Network servers handling concurrent requests usually show a multitasking architecture. Although Apache doesn't use it, we will now describe a common pattern using processes which works as follows:
A master server process (G)is waiting for incoming requests. Whenever a request from a client comes in, the master server establishes the connection and then creates a child server process by forking itself. The child server process handles the request(s) of the client while the master server process returns to its waiting state.
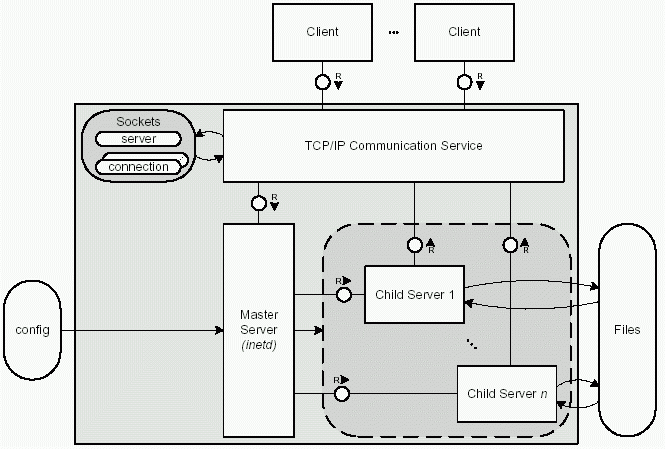
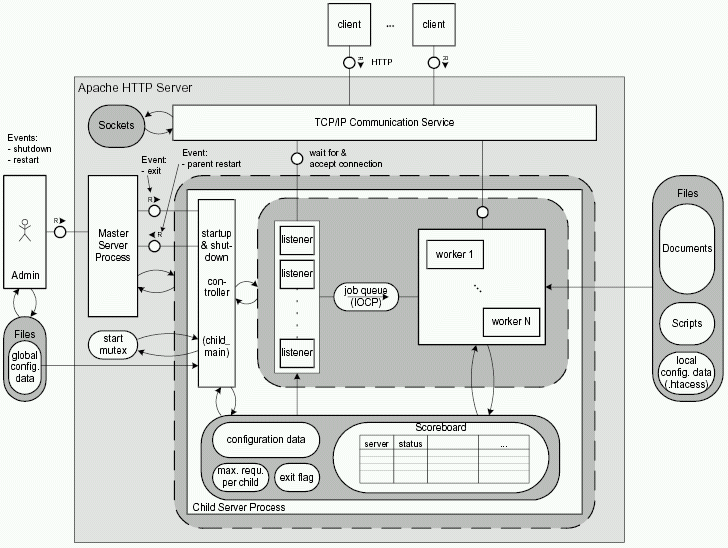
In figure 4.3 you see the structure of this kind of multiprocessing server. At the top there are one or many clients sending requests (R) to the server. The requests are received by the TCP/IP Communication Service of the operating system. The Master Server has registered itself as responsible for any request that comes in. Therefore the communication service wakes it up. The Master Server accepts the connection request so the communication service can establish the TCP/IP connection and create a new socket data structure.
The master server creates a child server process by doing a fork() system call. In figure 4.3 this is symbolized by the``write'' arrow from the master server to the storage area enclosed by a dashed line. The child server knows about the connection because it knows the connection socket. It can now communicate with the client until one of them closes the connection. Meanwhile the master server waits for new requests to arrive.
With TCP/IP, a connection end point has to be identified by the IP address of the machine and a port number (for example, the port for HTTP requests has number 80). The master server process registers itself as a listener for the port (which in turn becomes a server port). Note that a connection request arrives at the server port while the connection is established using a connection port. The major difference between a server and a connection port is that a server port is solely used to accept connections from any client. A connection port uses the same TCP/IP portnumber but is associated with one specific connection and therefore with one communication partner. Connection ports are used to transmit data and therefore the server port can remain open for further connection requests.
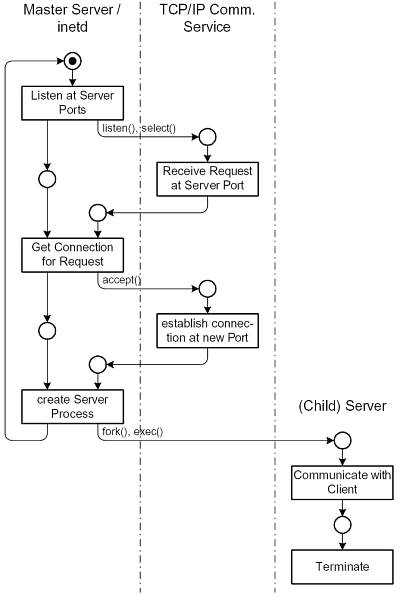
The behavior of the server is shown in figure 4.4. The system calls accept() or select() block4.1 the master server process until a request comes in. accept()waits for requests on one server port while select() is a means to observe multiple ports. In this case, after a request has been received by the TCP/IP Communication Service, the master server can establish the connection with the system call accept(). After that it creates a new process with fork(). If the request has to be handled by a different program, it has to be loaded and executed with exec().
The INETD is a typical server using the multitasking architecture described above. It waits for requests on a set of ports defined in the configuration file /etc/inetd.conf. Whenever a request comes in, inetd starts the (child) server program defined in the configuration file. That program then handles the request.
Apache also provides a mode of operation to work with the inetd. In this case, the inetd is the gatekeeper for the HTTP port (80) and starts Apache whenever an HTTP request arrives. Apache answers the request and exits.
This multiprocessing architecture is useful if the handling of the client request takes some time or a session state has to be kept by the (child) server because the communication between client and server does not end after the response to the first request.
HTTP, however, is a stateless protocol. No session information needs to be kept by the server -- it only needs to respond to one request and can ``forget'' about it afterwards. An HTTP server based on the inetd architecture would be inefficient. The master server would have to create a process for each HTTP connection, which would handle this one connection only and then die. While the master server creates a process it cannot accept incoming requests. Although process creation does not take a long time on modern operating systems, this gatekeeper function of the master server forms a bottleneck for the entire server.
All Apache Multitasking Architectures are based on a task pool architecture. At start-up, Apache creates a number of tasks (processes and/or threads), most of them are idle. A request will be processed by an idle task, therefore there's no need to create a task for request processing like the inetd described in section 4.3.1.
Another common component is the master server, a task controlling the task pool -- either control the number of idle tasks or just restart the server something goes wrong. The master server also offers the control interface for the administrator.
In the following, the preforking architecture will be presented as the first and most important architecture for unix systems. Then we present a selection of other Apache multitasking architectures and emphasize the differences concerning the preforking architecture.
The preforking architecture is based on a pool of tasks (processes or threads) which are playing 3 different roles:
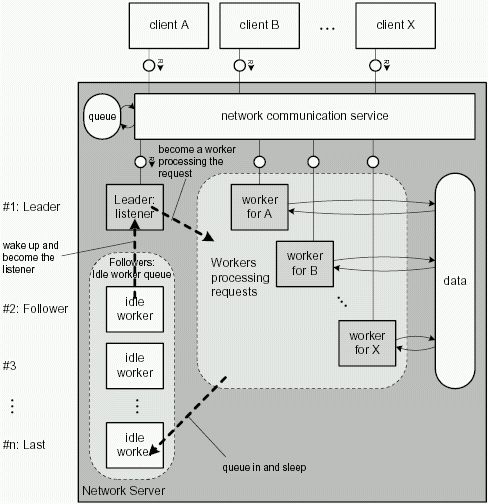
A description of the pattern can be found in [5]. Figure 4.5 shows the structure of the system: The listener is the leader. Only one task can be granted the right to wait for connection requests. If the listener gets a request, it hands over the right to listen and switches his role to worker, that means he processes the request using the connection he established as listener. If he's finished processing the request, he closes the connection and becomes an idle worker. That means he queues in waiting to become the listener. Usually an idle worker task will be suspended.
What are the differences between the server strategy described in section 4.3.1 and the leader-follower strategy? Firstly, an incoming request will be treated immediately by the listener task -- no new task has to be created. On the other hand there should always be a certain number of idle worker tasks to make sure there is always a listener. Secondly, there is no need to pass information about a request to another task because the listener just switches his role and keeps the information.
The task pool must be created at server start. The number of tasks in the pool should be big enough to ensure quick server response, but a machine has resource restriction. The solution is to control the number of tasks in the pool by another agent: the master server.
The Preforking architecture was the first multitasking architecture of Apache. In Apache 2.0 it is still the default MPM for Unix. The Netware MPM very closely resembles the Preforking functionality with the exception that it uses Netware threads instead of unix processes. Summarizingly the Preforking architecture of Apache takes a conventional Approach as each child server is a process by itself. That makes Preforking a stable architecture but also reduces performance.
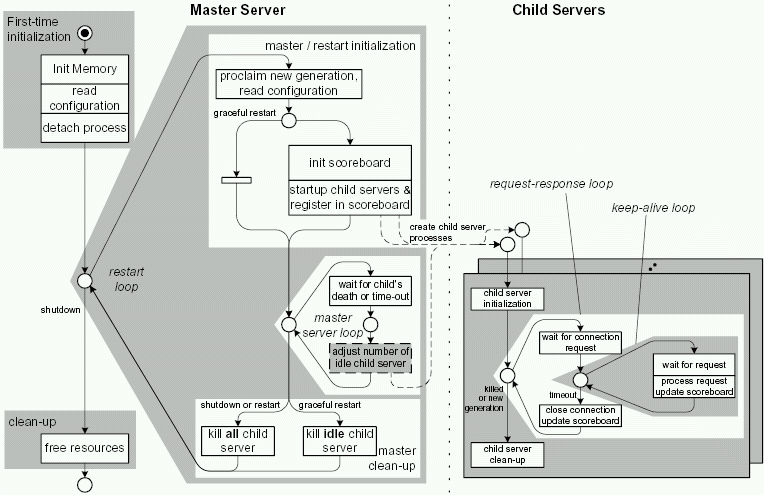
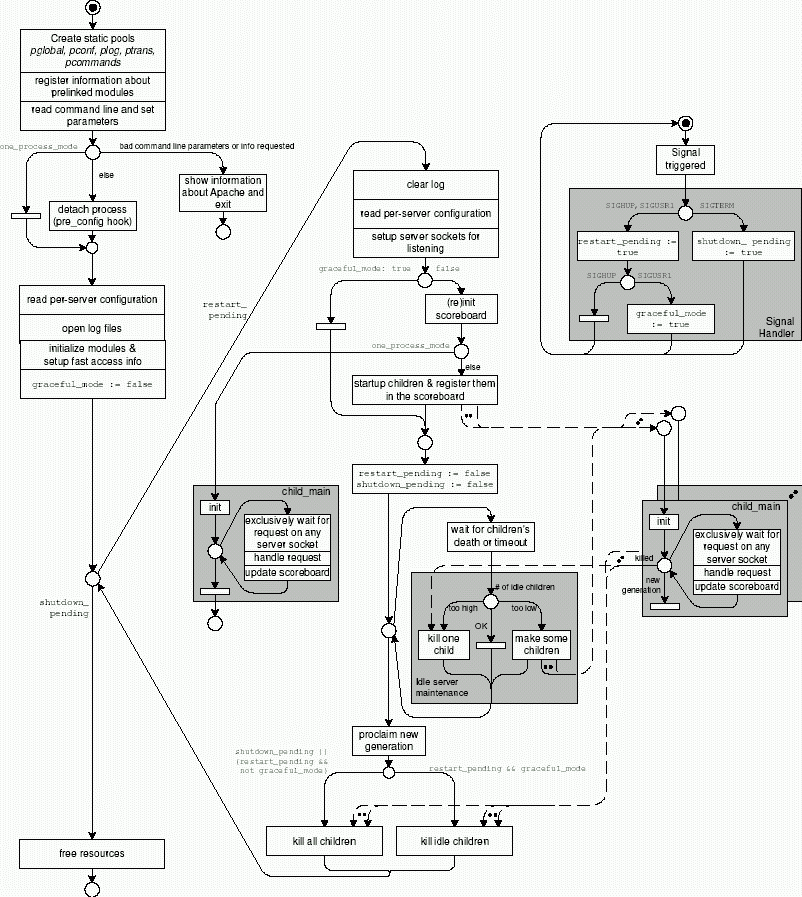
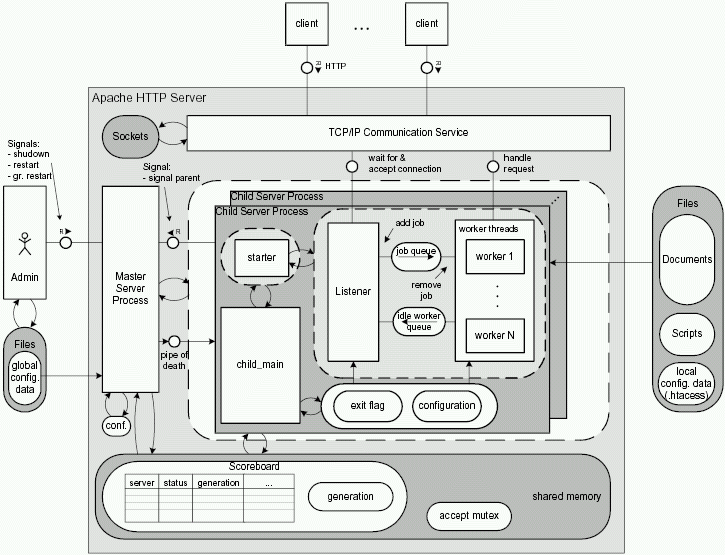
The structure diagram in figure 4.6 shows the structure of the Preforking architecture of Apache 2.0 and is important for the description of the behavior of Apache. You can see which component is able to communicate with which other component and which storage a component can read or modify. The block diagram for the Apache 2.0 MPM version of the Preforking architecture very much resembles the version that was used on Apache 1.3, however there is one difference: The Master Server uses a ``pipe of death'' instead of signals to shut down the child servers for a (graceful) restart.
The Preforking (G) architecture shown in figure 4.6 seems to be very similar to the inetd architecture in figure 4.3 at first sight. There is one master server and multiple child servers. One big difference is the fact that the child server processes exist before a request comes in. As the master server uses the fork() system call to create processes and does this before the first request comes in, it is called a preforking server. The master server doesn't wait for incoming requests at all -- the existing child servers wait and then handle the request directly.
The master server creates a set of idle child server processes, which register with the TCP/IP communication service to get the next request. The first child server getting a connection handles the request, sends the response and waits for the next request. The master server adjusts the number of idle child server processes within given bounds.
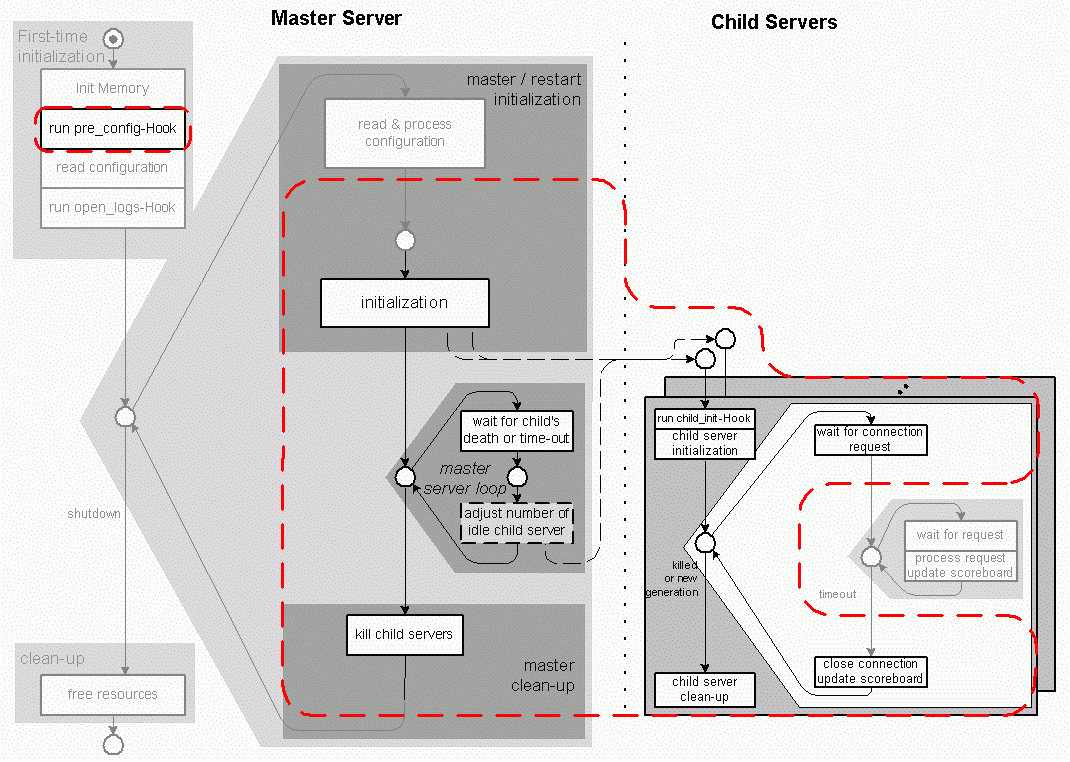
Figure 4.7 shows the overall behavior of the server, including the master server and the child servers.
Independently from the underlying multitasking architecture, Apache's behaviour consists of a sequence of the following parts which will be discussed individually for each of the architectures:
As each multitasking architecture distinguishes itself from others by using different means to create and organize child servers, the behaviour of different multitasking architectures mainly differs when child servers, also called workers are created during the restart loop and within the master server loop when the workers are monitored and replaced.
The server structure shown in figure 4.6 has to be set up at start-up (start processes, create sockets and pipes, allocate memory) and destroyed at shutdown. This is called activation and deactivation.
There are three types of initializations:
Every time the administrator forces a restart of the Apache server, it processes the restart loop which can be found in main(). (In Apache 1.3, the restart loop is located in the procedure standalone_main().) After reading the configuration, it calls ap_mpm_run() of the Preforking MPM.
The loop has the following parts:
Apache is controlled by signals. Signals are a kind of software interrupts. They can occur at any time during program execution.The processor stops normal program execution and processes the signal handler procedure. If none is defined in the current program, the default handler is used which usually terminates the current program. After the execution of the signal handler the processor returns to normal execution unless the program was terminated by the signal.
The administrator can send signals directly (using kill at the shell command prompt) or with the help of a script. The master server reacts to three signals:
In the upper right corner of figure 4.8 you see a small petri net describing the behavior of the signal handler of the master server. Apache activates and deactivates signal handling at certain points in initialization and in the restart loop. This is not shown in figure 4.8.
While the administrator controls the master server by signals only, the master server uses either signals or a pipe to control the number of child servers, the Pipe of Death. (Apache 1.3 used signals only).
|
For a shutdown or non-graceful restart, the master server sends a SIGHUP signal to the process group. The operating system ``distributes'' the signals to all child processes belonging to the group (all child processes created by the master server process). The master server then ``reclaims'' the notification about the termination of all child servers. If not all child processes have terminated yet, it uses increasingly stronger means to terminate the processes.
A graceful restart should affect primarily the idle child server processes. While Apache 1.3 just sent a SIGUSR1 signal4.2 to the process group, Apache 2 puts ``Char of Death'' items into the Pipe of Death (pod). The busy child servers will check the pipe after processing a request, even before comparing their generation. In both cases they set the die_now flag and terminate upon beginning a new iteration in the request-response loop
Table 4.1 lists the differences between a normal and a Graceful Restart (G).
The Master server of Apache 2.0 uses the Pipe of Death for inter-process communication with the child servers to terminate supernumerary ones and during graceful restart. All child servers of one generation share a pipe.
If the master server puts a Char of Death in the queue using ap_mpm_pod_signal() or sends CoD to all child servers with ap_mpm_pod_killpg(), these procedures also create a connection request to the listening port using the procedure dummy_connection() and terminate the connection immediately. The child server waiting for new incoming connection requests (the listener) will accept the request and skip processing the request as the connection is already terminated by the client. After that it checks the PoD which causes him to terminate. Busy child servers can continue serving their current connection without being interrupted.
In this loop the master server on the one hand controls the number of idle child servers, on the other hand replaces the child servers it just killed while performing a graceful restart.
While the restart loop can be found within the server core in main(), the master server loop it is located within the corresponding MPM, which in this case is the Preforking: ap_mpm_run() . (In Apache 1.3 it can be found in the procedure standalone_main() in the file http_main.c .)
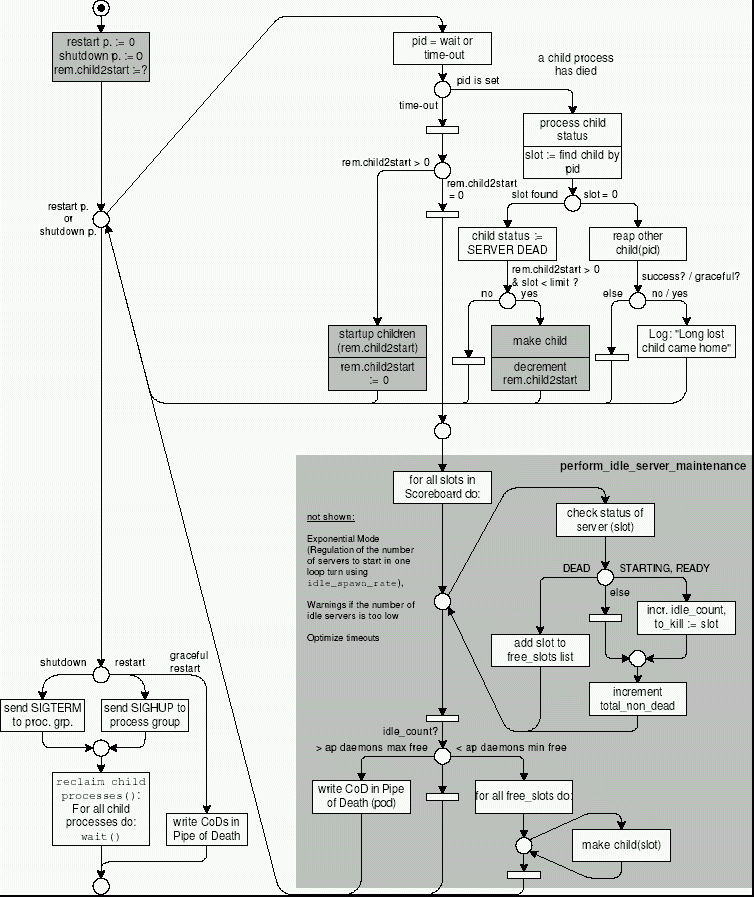
In figure 4.9 you see the details of the loop. The upper part deals with the reaction to the death of a child process and special issues of a graceful restart. The lower part is labeled ``perform idle server maintenance''. It shows a loop in which the master server counts the number of idle servers and gets a list of free entries in the scoreboard. It compares the number of idle children (idle_count) with the limits given in the configuration (ap_daemons_max_free and ap_daemons_min_free). If there are too many idle servers, it kills exactly one of them (the last idle server in the scoreboard). If the number of idle child servers is too low, the master server creates as many child server processes as needed (see exponential mode below).
The following remarks mainly deal with the graceful restart and the reaction to the death of a child process:
The lower part of figure 4.9 shows the behavior of the procedure perform_idle_server_maintenance() which is called whenever a time-out occurred and the graceful restart has been finished.
The master server counts the number of idle servers and the number of remaining slots (entries) in the scoreboard and compares it with three limits given in the configuration:
Example: ap_daemons_min_free is set to 5 but suddenly there is only 1 idle server left. The master server creates one child server and waits again. 2 idle servers are still not enough, so the master creates 2 more child servers and waits again. In the meantime, a new request occupies one of the new child servers. The master server now counts 3 idle child servers and creates 4 new ones. After the time-out it counts 7 idle child servers and resets the idle_spawn_rate to 1.
The Child Servers sometimes referred to as a workers form the heart of the HTTP Server as they are responsible for handling requests. While the multitasking architecture is not responsible for handling requests it is still responsible for creating child servers, initializing them, maintaining them and relaying incoming connections to them.
The master server creates child server processes using the fork() system call. Processes have separate memory areas and are not allowed to read or write into another processes' memory. It is a good idea to process the configuration once by the master server than by each child server. The configuration could be stored in a shared memory area which could be read by every child server process. As not every platform offers shared memory, the master server processes the configuration files before it creates the child server processes. The child server processes are clones of the master server process and therefore have the same configuration information which they never change.
Whenever the administrator wants to apply changes to the server configuration, he has to advice the master server to read and process the new configuration data. The existing child server processes have the old configuration and must be replaced by new processes. To avoid interrupting the processing of HTTP requests, Apache offers the ``graceful restart'' mode (see section 4.3.3), which allows child servers to use the old configuration until they have finished processing their request.
The initialization of a child server can be found in the corresponding MPM (Preforking: child_main(), Apache 1.3: child_main()). It consists of the following steps (see also figure 4.13):
The Preforking architecture uses an accept mutex(G) to distribute incomming connections among multiple child servers. The accept mutex makes sure that only one child server process exclusively waits for a TCP request (using the system call accept()) -- this is what a listener does. The Accept Mutex4.4 is a means of controlling access to the TCP/IP service. It is used to guarantee that, at any time, exactly one process waits for TCP/IP connection requests.
There are various implementations of the Accept Mutex for different OS configurations. Some need a special initialization phase for every child server. It works this way:
Once a connection is received by a child server, the scope of responsibility of the multitasking architecture ends. The child server calls the request handling routine which is equally used by any multitasking architecture.
In an inetd server (see section 4.3.1), there is only one process waiting for a TCP/IP connection request. Within the Apache HTTP server, there are possibly hundreds of idle child servers concurrently waiting for a connection request on more than one server port. This can cause severe problems on some operating systems.
Example: Apache has been configured to listen to the ports 80, 1080 and 8080. 10 Idle child server processes wait for incoming TCP/IP connection requests using the blocking system call select() (they are inactive until the status of one of the ports changes). Now a connection request for port 1080 comes in. 10 child server processes wake up, check the port that caused them to wake up and try to establish the connection with accept(). The first is successful and processes the request, while 9 child servers keep waiting for a connection at port 1080 and none at port 80 and 8080! (This worst-case scenario is only true for blocking4.5 accept())
Therefore in a scenario where there are multiple child servers waiting to service multiple ports the select() accept() pair is not sufficient to achieve mutual exclusion between the multiple workers. Therefore Preforking has to use the accept mutex.
In general it is a bad idea to waste resources of the operating system to handle concurrency. As some operating systems can't queue the child server processes waiting for a connection request, Apache has to do it.
A multiprocessing architecture's main task is to provide a fast responding server which uses the underlying operating system efficiently. Usually each architecture has to accept a trade-off between stability and performance.
In case of a HTTP server, the multitasking architecture describes the strategy how to create and control the worker tasks and how they get a request to process.
The first choice concerns the tasks: Depending on the platform, the server can use processes or threads or both to implement the tasks. Processes have a larger context (for example the process' memory) that affects the time needed to switch between processes. Threads are more lightweight because they share most of the context, unfortunately bad code can corrupt other thread's memory or more worse crash all threads of the process.
The next aspect affects the way how tasks communicate (Inter Task Communication). In general, this can be done by shared memory, signals or events, semaphores or mutex and pipes and sockets.
As all MPMs use a Task Pool strategy (idle worker tasks remain suspended until a request comes in which can immediately be processed by an idle worker task), there must be a means to suspend all idle worker tasks and wake up one whenever a request occurs. For this, an operating system mechanism like a conditional variable or a semaphore must be used to implement a mutex. The tasks are suspended when calling a blocking procedure to get the mutex.
The server sockets are a limited resource, therefore there can only be one listener per socket or one listener at all. Either there are dedicated listener tasks that have to use a job queue to hand over request data to the worker tasks, or all server tasks play both roles: One idle worker becomes the listener, receives a request and becomes a worker processing the request.
Finally a task can control the task pool by adjusting the number of idle worker tasks within a given limit.
Apache includes a variety of multitasking architectures. Originally Apache supported different architectures only to support different operating systems. Apache 1.3 had two major architectures which had to be defined at compile time using environment variables that the precompiler used to execute macros which in turn selected the correspondig code for the operating system used:
An MPM's responsibility is located within the main loops of Apache. The main server will do all initialization and configuration processing before calling the method ap_mpm_run() in main() to hand over to the MPM.
It is the MPM's responsibility to take care of starting threads and/or processes as needed. The MPM will also be responsible for listening on the sockets for incoming requests. When requests arrive, the MPM will distribute them among the created threads and/or processes. These will then run the standard Apache request handling procedures. When restarting or shutting down, the MPM will hand back to the main server. Therefore all server functionality is still the same for any MPM, but the multiprocessing model is exchangeable. Figure 4.10 shows the responsibility of an Apache MPM in the overall behavior of Apache (see also figure 4.7). The dotted line marks the actions for which the MPM takes responsibility.
Version 2.0 currently includes the following MPMs:
The Windows multitasking architecture has some significant differences compared to the preforking architecture. It uses threads(G) instead of processes and the number of child servers is not variable but fixed. Threads are used because threads are a lot more performant than windows processes. There are two Windows processes in this multitasking architecture: The worker process (child server process) contains the threads which handle the HTTP requests, while the supervisor process (master process) makes sure that the worker process works correctly. For connection distribution to the workers a job queue is used. Additionally the Apache 2.0 MPM version of this multitasking architecture uses a windows NT operating concept called I/O Completion Port instead of a job queue when used on Windows NT platforms. The version 1.3 of this architecture as well as the Windows32 version of the Apache 2.0 MPM use a single listener thread to accept connections. The WindowsNT variant of the MPM uses one listener per port that Apache has to listen on.
Figure 4.11 shows the system structure of the server using the WinNT MPM: The Master Server Process creates the Child Server Process and then monitors the Child Server in case the process dies.
The initialization procedure of the Win32 multitasking architecture closely resembles the one described for the Preforking architecture. All initialization is similar to the point where the Preforking MPM is called or the Apache 1.3 architecture starts to create child server processes.
Both, the 1.3 and the 2.0 version use the master server process as the supervisor process. That in turn creates the second process that contains all the worker threads. When started the worker process only contains a single master thread which then spawns the fixed number of worker threads. These correspond to the child server processes within the Preforking architecture. The Windows multitasking version uses a fixed number of threads since idle threads impose almost no performance issue. Therefore as many threads as are desirable for optimum performance are started right away and the server can be used to its maximum capability, without the overhead and delay of spawning new processes dynamically.
Both Windows multitasking architectures only support graceful restart or shutdown.
A Variety of inter-process communication mechanisms is used in this multitasking architecture. As Windows does not support signals, the native Windows concept of events is used for communication between the supervisor or master server process and the worker process. Here events are used for signaling:
However job queue or IOCP respectively are also used by the listeners to communicate arriving connections to the worker threads for request handling.
The master server process is called the supervisor process when entering the restart loop. It contains only one thread and is used to monitor the second process called the worker process to be able to restart it in case it crashes. The user can communicate with this specific process using the control manager which can be found on any windows platform. The control manager then sends an event to the server which signals a restart or shutdown. Additionally the apache server supplies command line options that can be used for signaling.
The worker process contains three kinds of threads: One master thread, a fixed number of worker threads and one or multiple listeners. The master starts one or multiple listeners which accept the connection requests and put the connection data into a job queue (like a gatekeeper). The worker threads fetch the connection data from the queue and then read and handle the request by calling the core's request handling routine which is used by all multitasking architectures. The communication between the master and the worker threads is also accomplished via the job queue. However the only communication necessary between master and worker thread is to signal a worker to exit. If the master thread wants to decrease the number of worker threads due to a pending shutdown or restart, it puts "die"-jobs into the queue.
Instead of a selfmade job queue, the MPM of Version 2.0 uses the IOCP on Windows NT plattforms. The advantage of the I/O Completion Port is that it enables the server to specify an upper limit of active threads. All worker threads registering with the IOCP are put to sleep as if registering with a job queue. When any of the events the IOCP is responsible for occurs one worker thread is woken to handle the event (in Apache that can only be a new incomming connection request). If however the limit of active threads is exceeded, no threads are woken to handle new requests until another thread blocks on a synchronous call or reregisters with the IOCP. That technique is used to prevent excessive context switching and paging due to large numbers of active threads.
Worker Threads are kept pretty simple in this architecture model. As they can share any memory with their parent process (the worker process) they do not need to initialize a lot of memory. All they maintain is a counter of requests that the thread processed. The MPM version also keeps a variable containing the current operating system version so that either the job queue or the IOCP is choosen when trying to get a connection. Therefore the initialization is very short.
After intialization the worker registers with the IOCP or the job queue to retrieve a connection which it can handle. After receiving the connection it calls the core's request processing routine. It continues to do that until it is given a ``die''-job from the queue, which would cause it to exit.
The Worker MPM is a Multiprocessing Model for the Linux/Unix Operating System Platform. In contrast to the Preforking and WinNT Model, this MPM uses a combination of a multiprocessing and a multithreading model: It uses a variable number of processes, which include a fixed number of threads (see figure 4.12). The preforking model on process level is extended by a job queue model on thread level.
Still the master server process adjusts the number of idle processes within a given range based on server load and the max_child, max_idle and min_idle configuration directive. Each child process incorporates a listener thread, which listens on all ports in use by the server. Multiple processes and therefore multiple listener threads are mutually excluded using the accept mutex like in the Preforking Model.
Initialization of a child server is a more complex task in this case, as a child server is a more complex structure. First the master server creates the child process, which in turn starts a so called starter thread that has to set up all worker threads and a single listener thread. This behavior is reflected in figure 4.12.
Within each child process, the communication between the listener and all worker threads is organized with two queues, the job queue and the idle queue. A listener thread will only apply for the accept mutex if it finds a token in the idle queue indicating that at least one idle worker thread is waiting to process a request. If the listener gets the mutex, it waits for a new request and puts a job item into the queue after releasing the accept mutex. Thus it is ensured that a incoming request can be served by a worker immedialtely.
After completing a request or a connection with multiple requests (see section 2.3.4 for details) the worker thread registers as idle by putting a token into the idle queue and returns to wait for a new item in the worker queue.
Advantages of this approach are that it combines the stable concept of multiprocessing with the increased performance of a multithreading concept. In case of a crash, only the process that crashed is affected. In multithreading a crashing thread can affect all threads belonging to the same parent process. Still threads are a lot more lightweight and therefore cause less performance overhead during start-up and consume less memory while running.
The MPMs mentioned so far are the MPMs used most often. Additionally there are other MPMs available. However most of these mainly serve an experimental purpose and are seldom used in productive environments.
This MPM uses the preforking (Leader-Follower, see also figure 4.5 and the pattern description in [5](G)) model on both process and thread level using a sophisticated mechanism for the followers queue:
Each Child Process has a fixed number of threads like in Worker MPM. However, threads are not distinguished into worker and listener threads. Idle workers are put onto a stack. The topmost worker is made listener and will upon receiving a connection immediately become a worker to handle the connection itself. The worker on the stack below him will become the new listener and handle the next request. Upon finishing a request the worker will return to the top of the stack.
This approach addresses two performance issues. First there is no delay due to handing a connection to a different task using a job queue, since each thread simply handles the connection it accepts. Secondly since follower threads are organized in a stack, only one thread is woken when the listener position becomes available. The overhead that is caused when all threads are woken to compete for the mutex is avoided.
A thread returning to the stack is put on top. Therefore it is most likely that a thread on top will handle more requests than a thread at the bottom. Considering the paging techniques for virtual memory that most operating systems use, paging is reduced as more often used threads do more work and thus are less likely to be swapped to the hard disk.
Based on the Worker MPM, this experimental MPM uses a fixed number of processes, which in turn have a variable number of threads. This MPM uses also uses the preforking model on both process and thread level. The advantage of this approach is that no new processes have to be started or killed for load balancing.
An advantage of this MPM: Each process can have a separate UserID, which in turn is associated with different file access and program execution rights. This is used to implement virtual hosts with different rights for different users. Here each virtual host can have its own process, which is equipped with the rights for the corresponding owner, and still the server is able to react to a changing server load by creating or destroying worker threads.
| Apache Modeling Portal 2004-10-29 |